
Recentemente recebi uma pergunta em meu e-mail e achei super bacana para um post aqui no blog. A questão era sobre como fazer um Group By no MongoDB.
Para fazer operações de agregação de dados, nós devemos usar o lindo Aggregation Framework, do qual eu já falei um pouco nos posts sobre views materializadas e joins.
Resumidamente, no Aggregation Framework os dados são transformados em etapas, passando por um pipeline, onde o resultado de um estágio é o insumo (entrada) do estágio seguinte.
Para trabalhar com o Aggregation Framework nós usamos o Aggregation Pipeline Builder, que é uma ferramenta visual que permite criar pipelines de dados, e depois importar o pipeline para a sua linguagem de programação favorita, além de permitir salvar o pipeline para execuções posteriores.
O Aggregation Pipeline Builder está disponível no MongoDB Atlas, o que é bem fofo porque não precisamos instalar uma aplicação cliente, se estivermos usando o MongoDB na Nuvem.
Neste post eu mostrarei como fazer um Group By usando o MongoDB Compass , que é uma ferramenta visual que permite acessar tanto o MongoDB instalado no servidor quanto o MongoDB na Nuvem.
Sobre o Group By
Antes de colocar a mão na massa, é importante entender o estágio group by.
O primeiro passos é dar uma olhada na documentação oficial, que tem várias informações super importantes.
Para fazer um Group By no MongoDB, usamos o estágio $group (lembrando que os estágios sempre começam com $), nele devemos informar qual o atributo usado para a agregação e qual a operação que será feita com os documentos agregados.
Sobre o atributo usado para a agregação, se ele não for informado o MongoDB calculará os valores acumulados para todos os documentos de entrada do estágio. E sobre as operações feitas com os documentos agrupados, podemos fazer uma contagem, soma, desvio padrão, máximo, mínimo, primeiro, último… Entre outros… Por isso é bom ver a documentação oficial.
Vamos lá…
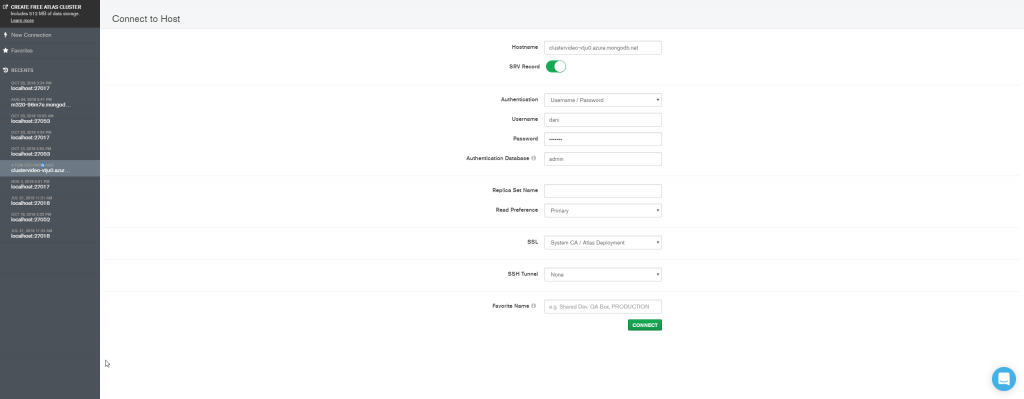
Abra o MongoDB Compass, preencha os dados da conexão com o seu MongoDB.
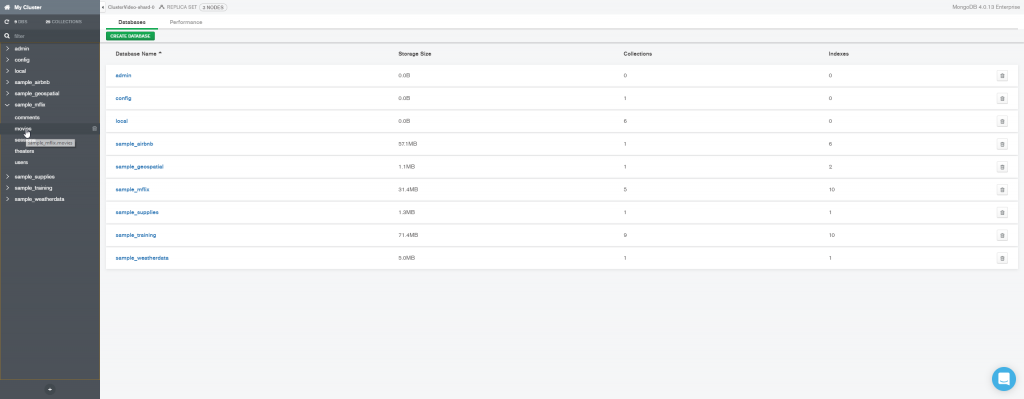
Escolha a coleção que contém os dados que você quer agrupar. E clique sobre ela.
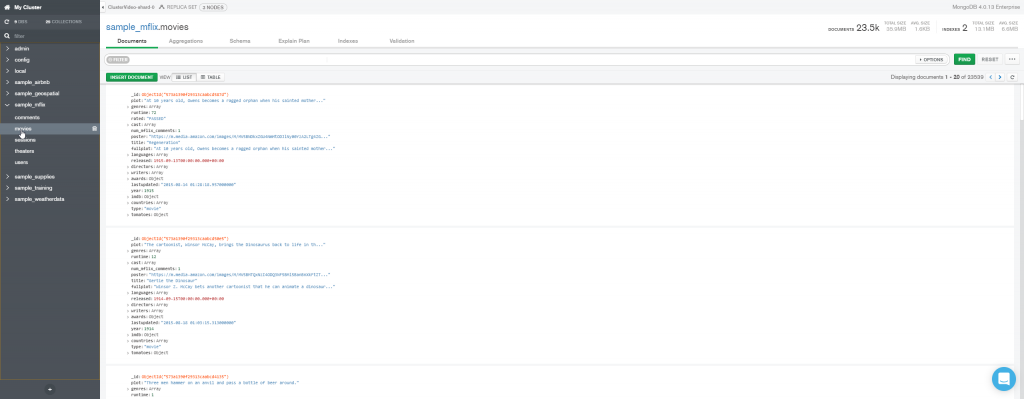
Clique no menu Aggregations
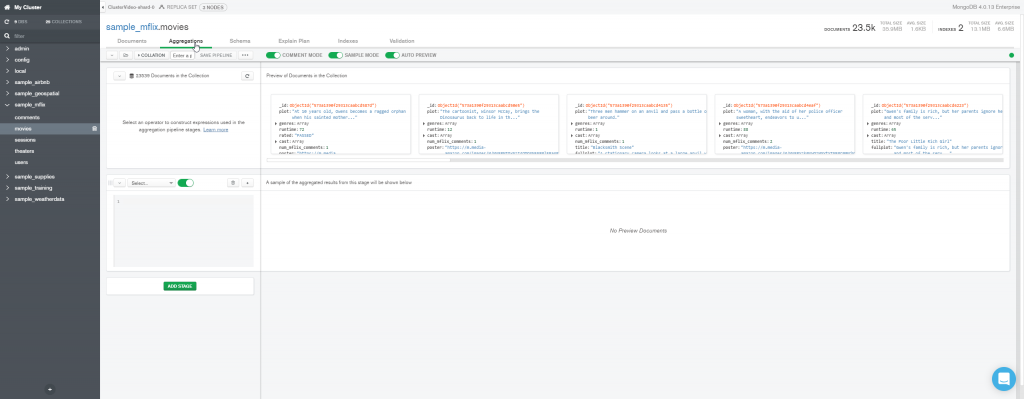
Escolha o estágio $group
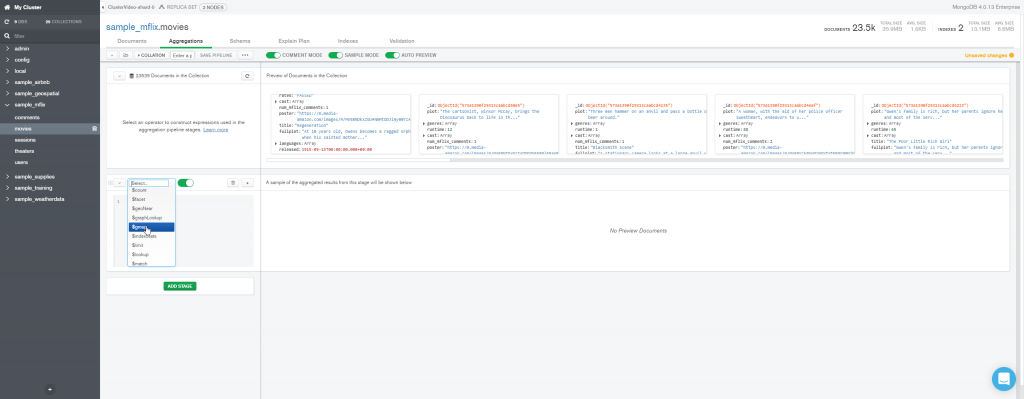
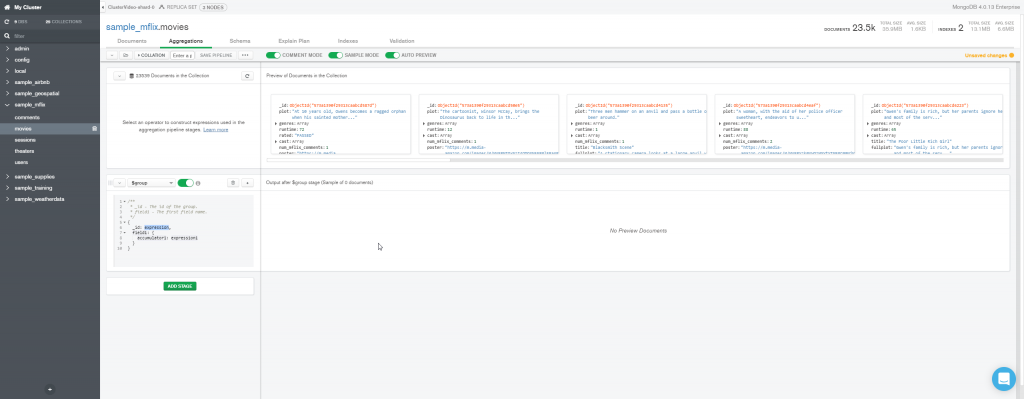
Faremos dois exemplos, no primeiro queremos fazer uma soma de todos os documentos da coleção. Por isso o parâmetro _id será nulo, o resultado da soma ficará no atributo contagem.
O estágio que iremos executar é equivalente ao seguinte comando SELECT
SELECT COUNT(*) AS contagem FROM movies
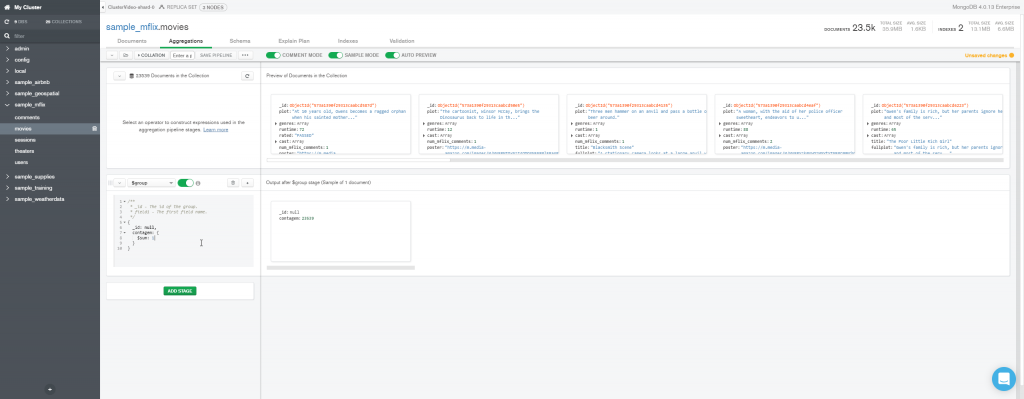
Agora suponha que queremos fazer a contagem de documentos, agrupando-os pelo atributo runtime
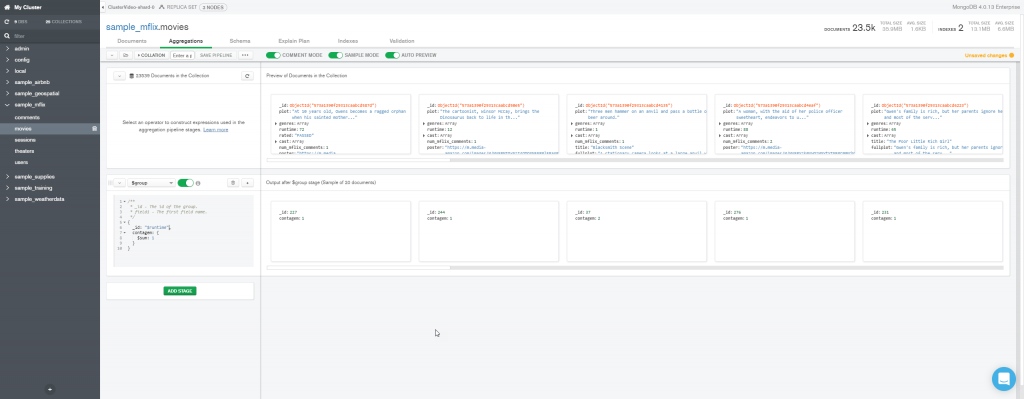
Este estágio equivale ao comando
SELECT COUNT(*) AS contagem FROM movies GROUP BY runtime
E se quisermos somar o número de comentários por runtime?

Este comando equivale a
SELECT SUM(num_mflix_comments) AS contagem FROM movies GROUP BY runtime
Observe que o nome dos atributos está entre aspas e começa com $.
Para terminar podemos salvar o pipeline.
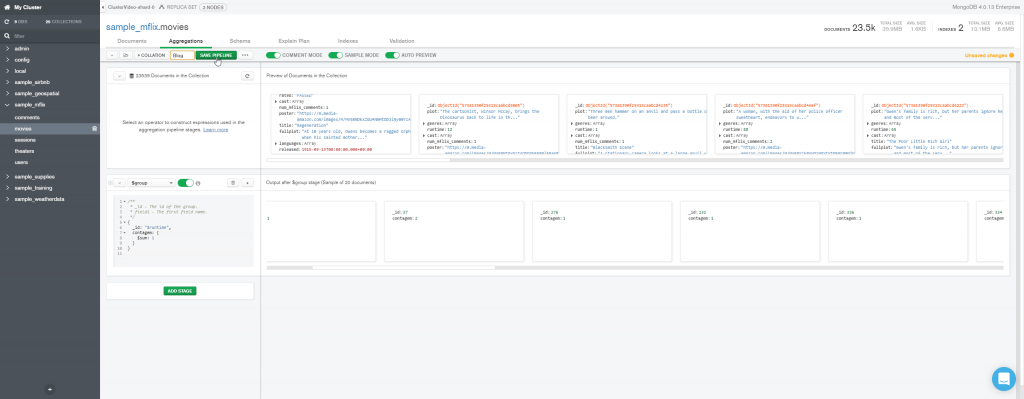
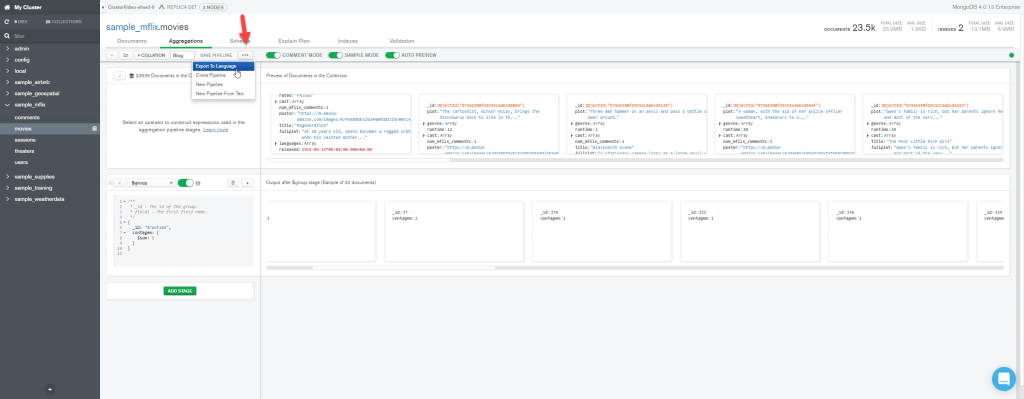
E/ou exportar para a linguagem de programação na qual desenvolvemos o nosso sistema.

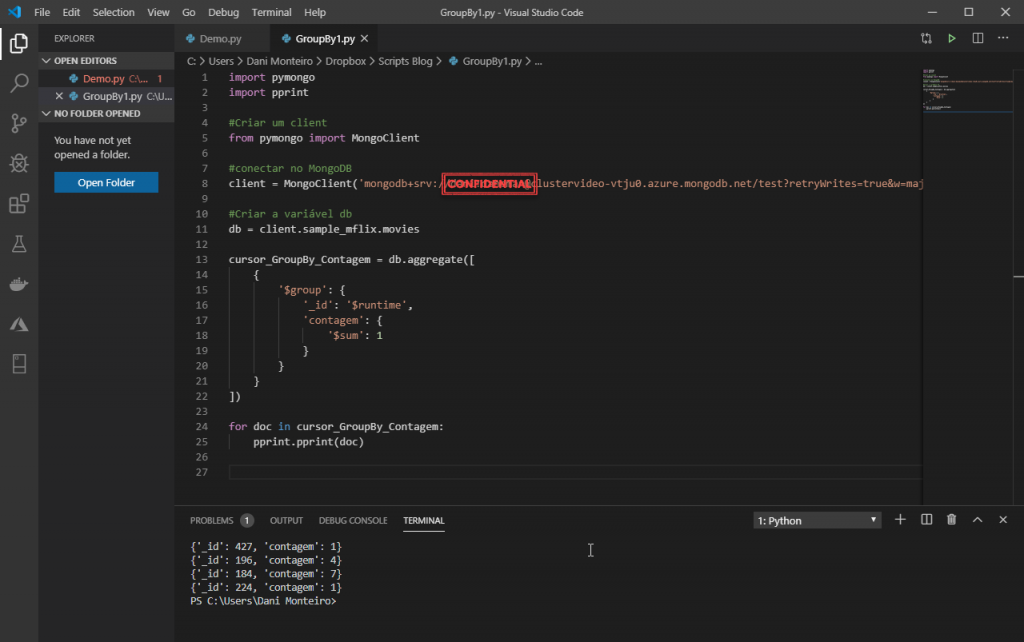
Eu amo programar em Python e por isso, já que exportamos o nosso pipeline para esta linguagem, eu fiz um exemplo bem simples de como executar o nosso group by, e imprimir os resultados (o código está no meu github)
Conclusão
O MongoDB é um banco de dados muito poderoso e tem vários recursos que valem a pena ser entendidos e usados.
Quando falamos do Aggregation Framework existem diversos operadores que possibilitam uma análise complexa e completa dos dados.
Demos o primeiro passo, agora cabe a você criar seus pipelines e dividir comigo e com os leitores do blog as suas conclusões, afinal de contas juntos fica bem mais divertido!

Gostou do que leu?
Inscreva-se e receba dicas como essa no seu e-mail!

