
Um Cenário para utilizar a replicação no MongoDB
Imagine que você criou um banco de dados MongoDB, criou suas aplicações e tudo funciona lindamente, mas infelizmente o servidor de banco de dados apresentou um problema e suas aplicações pararam de funcionar. Parece surreal? Mas não é! Os servidores de banco de dados podem apresentar problemas mas as suas aplicações não devem parar, por isso é indispensável criar soluções de alta disponibilidade, como a replicação no MongoDB.
Uma solução de alta disponibilidade mascara os efeitos das falhas de um hardware ou software e mantém a disponibilidade dos aplicativos, de modo a minimizar o tempo de inatividade percebido pelos usuários.
Se você acha que ser um desenvolvedor iniciante te isenta da responsabilidade de pensar na alta disponibilidade, achou errado! Porque como você verá adiante as soluções de alta disponibilidade podem causar impactos nos comandos de manipulação de dados.
Solução de alta disponibilidade no MongoDB
A solução de alta disponibilidade nativa do MongoDB é a replicação, que consiste basicamente em manter cópias idênticas dos dados em mais de um nó do cluster, desta forma se algum nó falhar os dados estejam disponíveis de forma automática.
Se você ainda não se convenceu dos motivos de usar a replicação vou listar mais alguns:
• redundância dos dados uma vez que são mantidas cópias em mais de um nó do cluster;
• alta disponibilidade por que se um nó apresenta problemas, os outros assumem de forma automática (você não precisa alterar sua aplicação);
• distribuição da carga de leitura as operações de escrita normalmente ocorrem em um único nó. Mas as operações de leitura são distribuídas entre os outros nós;
• distribuição geográfica dos dados com a replicação é possível você direcionar os dados para locais mais próximos dos seus consumidores diminuindo a latência de acesso
Conceitos importantes
- Replicaset é um conjunto de servidores (normalmente afastados geograficamente) compondo uma unidade na qual os clientes farão conexões, ou seja, em um ambiente replicado a conexão não é feita a um servidor, mas a um conjunto deles;
- Replicaset Factor é o número que indica a quantidade de servidores que fazem parte da replicação;
- O MongoDB utiliza a arquitetura Master- Slave, isso significa que o servidor Master (Primary) recebe os dados provenientes da inclusão, e estes dados são repicados para os servidores slave (Secondary).
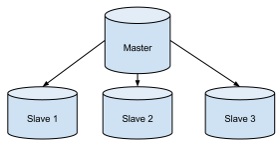
- A leitura dos dados pode acontecer em qualquer servidor.
Arbitro
Imagine o cenário onde temos 3 servidores no replicaset e 2 servidores caem… Neste caso teremos um problema de disponibilidade porque o MongoDB não conseguirá atribuir ao servidor restante o papel de primário, porque existe um conceito de votação, é preciso que mais da metade dos servidores votem em um servidor para que ele seja o primário. E se só existe um servidor no replicaset, o voto dele (nele mesmo) não é o suficiente. Neste caso é preciso ter um arbitro, que é o servidor que tem como única função votar no servidor primário, ou seja, o arbitro não possui dados;
Momento dica da Dani… No contexto da replicação eu costumo criar o arbitro com uma porta bem diferente dos demais servidores.
Write Concern
Quando existe replicação é esperado que os mesmos dados existam em todos os servidores, entretanto temos que lembrar que os servidores estão distribuídos geograficamente e pode existir uma latência entre a inclusão dos dados no master (lembrando que os dados são incluídos sempre nele) e a replicação dos dados para o slave.
Por padrão no MongoDB o parâmetro write concern tem o valor 1, que indica que os dados são considerados persistidos após a inclusão no servidor master. O que nem sempre é ideal no seu cenário de negócio. Imagina que você fez a alteração dos dados, ela foi efetivada no seu servidor master, porém antes da alteração ser replicada para os servidores slaves o servidor master caiu… E um dos slaves (que não possui a alteração) assumiu o lugar do master. Concorda comigo que você tem um problema com a consistência dos dados? Por isso eu te disse no começo deste post que você, desenvolvedor iniciante, também é responsável por analisar e opinar na escolha da estratégia de alta disponibilidade porque ela vai causar impactos no seu trabalho. O write concern pode ser “setado” nos comandos de inclusão, exclusão e alteração. Lembrando que quanto maior o write concern menor é o desempenho do banco de dados. O que é mais importante? Avalie a necessidade da sua aplicação, pois não existe uma resposta certa para esta questão.
Outro parâmetro importante é o Journaling que indica que para um comando ser considerado efetivado, a alteração deve ter sido gravada no disco.
Parâmetros do write concern
- w
- Indica a quantidade de servidores para onde a operação (inclusão, exclusão, alteração) deve ter sido propagada para que o MongoDB considere a operação bem sucedida;
- Permite que seja usada a opção “majority” que indica que a operação será bem sucedida se tiver sido efetuada na maioria dos servidores;
- j
- um booleano que quando possui o valor true indica que a operação só será bem sucedida após a quantidade de servidores informada no parâmetro w, gravar a operação em disco
- wtimeout
- tempo em milissegundos para o write concern. Só é aplicável se o parâmetro w é diferente de zero
Exemplo de insert com write concern
- db.NomeColeçao.insert ({Documento} , { w: “majority”, j: true, wtimeout: 5000})
Pré treino
- Para simular localmente a replicação é preciso:
- Criar um diretório de dados para cada servidor que fará parte da replicação;
- Para iniciar os serviços de cada servidor:
- atribuir portas diferentes;
- atribuir o mesmo nome para o replicaset;
- atribuir um nome para cada arquivo de log;
- Informar o path do diretório de dado de dados;
- Sintaxe: mongod –-port 27012 –replSet r1 –dbpath ./db1 –logpath ./log.1
- Para iniciar o replicaset é necessário executar o mongo.exe, conctando-se a um dos servidores já iniciados
- No mongo.exe criar uma variável com as configurações da replicação;
- Config = { _id : “r1″ , members : [ { _id:0, host:”localhost:27022″ }, { _id:2, host:”localhost:27023″ }, { _id:3, host:”localhost:27024” } ] } (atenção ao número da porta atribuído quando iniciamos os serviços mongod de cada servidor);
- Iniciar o replicaset;
- rs.initiate ( Config )
- Para saber como está a “saúde“ do replicaset que acabamos de criar usamos a função rs.status()
- Uma das informações relevantes é saber qual papel cada servidor assumiu (Primary ou Secondary) e se todos os servidores estão ativos;
- Para verificar se um servidor é o Master é possível usar a função db.isMaster();
- Um servidor em um ambiente replicado não é primário! Ele está primário e isso pode mudar a qualquer momento.
Treino
Momento super esperado! vamos simular a replicação na sua máquina, seguindo um roteiro super simples. Importante dizer que:
- Eu estou usando o sistema operacional IOS, mas há poucas diferenças se você estiver usando o windows 🙂
- Ao copiar os comandos lembre que este é um exemplo, que todos os servidores estão na mesma máquina, o que não vai ocorrer em um ambiente produtivo.
- Sinta-se livre para escolher os paths!
- Treine, teste, avalie, erre, corrija, pesquise e comece tudo de novo!
1 . Crie os diretórios para log e para dados
- Diretório raiz
- cd /Volumes/MyHD/CursoMongoDB/MongoDB
- mkdir dbRepSet
- Diretório dos servidores
- cd /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet
-
- mkdir db1
- mkdir db2
- mkdir db3
- mkdir arb
Ponto de atenção! Parâmetros para iniciar os servidores:
- Atenção aos parâmetros usados quando iniciamos os servidores:
- /Volumes/MyHD/CursoMongoDB/MongoDB/bin/mongod = Path do executável mongod (daemon)
- –port 27052 = porta utilizado para o servidor
- –replSet r1 = nome do replicaset, que será igual para todos os servidores que fazem parte dele
- –dbpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/db1 = path do diretório de dados
- –logpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/log.1 = path do arquivo de log
2 . Crie os nós do cluster
- Execute um comando em cada terminal (no IOS)
- No windows utilize o prefixo start /b antes de cada comando e execute todos no mesmo prompt
- /Volumes/MyHD/CursoMongoDB/MongoDB/bin/mongod –port 27052 –replSet r1 –dbpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/db1 –logpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/log.1
- /Volumes/MyHD/CursoMongoDB/MongoDB/bin/mongod –port 27053 –replSet r1 –dbpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/db2 –logpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/log.2
- /Volumes/MyHD/CursoMongoDB/MongoDB/bin/mongod –port 27054 –replSet r1 –dbpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/db3 –logpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/log.3
- /Volumes/MyHD/CursoMongoDB/MongoDB/bin/mongod –port 30000 –replSet r1 –dbpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/arb –logpath /Volumes/MyHD/CursoMongoDB/MongoDB/dbRepSet/arb.log
3 . Configure a replicação
- Escolher um dos servers e executar o mongo;
- /Volumes/MyHD/CursoMongoDB/MongoDB/bin/mongo –port 27052
- Configurar a replicação
- Config = { _id : “r1″ , members : [ { _id:0, host:”localhost:27052″ }, { _id:2, host:”localhost:27053″ }, { _id:3, host:”localhost:27054” } ] }
- Iniciar a replicação;
- rs.initiate ( Config )
- Para saber como está a saúde do replicaset que acabamos de criar vamos usar o método status();
- rs.status()
- Para verificar se o servidor é o master;
- db.isMaster()
- Configurar o arbitro (precisa estar conectado no primary);
- rs.addArb(localhost:30000)
- Para saber como está a saúde do replicaset ver o status e verificar se o arbitro foi incluído corretamente executar o método status() novamente
- rs.status()
4. Divirta-se!
Faça consultas, derrube servidores, inclua dados… Comece de novo…
Conclusão
Neste post conversamos sobre a replicação no MongoDB, que é uma estratégia para a alta disponibilidade dos dados, uma vez que os mesmos dados existem em vários servidores.
Para um desenvolvedor iniciante conhecer a replicação é importante porque ela pode ser o motivo de erros aparentemente inexplicáveis nos comandos de inclusão, exclusão e alteração dos dados.
Estamos há algum tempo conversando sobre MongoDB, espero que estes posts tenham te ajudado e você esteja seguro para utilizar o este banco de dados fantástico no seu dia dia.
Se você tem alguma dúvida, é só me procurar no Twitter, ou no facebook, ou comentando este post, ou no formulário de contato. Não se preocupe… Eu sempre respondo (mesmo que seja para avisar que estou pesquisando).
Referências
https://technet.microsoft.com/pt-br/library/bb522583(v=sql.105).aspx
https://severalnines.com/sites/default/files/repset.png

Gostou do que leu?
Inscreva-se e receba dicas como essa no seu e-mail!

