no MongoDB!")
Porque você precisa conhecer o particionamento (sharding) no MongoDB ?
Sharding é um método para particionar seus dados. Imagina que sua coleção cresceu muito e o desempenho da sua aplicação está se degradando… Como proceder? Neste caso o MongoDB oferece um recurso nativo chamado sharding que divide os dados da sua coleção entre vários servidores.
Escalar horizontalmente e Escalar verticalmente
Grandes conjuntos de dados ou aplicativos de alto throughput podem desafiar a capacidade de um único servidor. Existem dois métodos para abordar o crescimento do sistema: escalar verticalmente e horizontalmente.
Escalar verticalmente envolve aumentar a capacidade de um único servidor, adicionando um nova CPU, aumentando a memória RAM, aumentando a quantidade ou alterando o tipo dos discos. As limitações na tecnologia disponível podem restringir uma única máquina de ser suficientemente poderosa para uma determinada carga de trabalho. Além disso, os provedores baseados em nuvem possuem tetos rígidos com base em configurações de hardware. Como resultado, existe um máximo prático para escala vertical.
Escalar horizontalmente envolve dividir o conjunto de dados do sistema e dividi-lo entre vários servidores, incluindo servidores adicionais para aumentar a capacidade, se for necessário. Embora a velocidade ou capacidade global de uma única máquina possa não ser alta, cada máquina lida com um subconjunto dos dados, proporcionando uma melhor eficiência se comparada a um único servidor de alta velocidade e capacidade. Expandir a capacidade requer somente a adição de servidores conforme necessário, o que tende a ter um custo geral mais baixo do que o hardware de ponta para uma única máquina. O trade off é uma complexidade crescente na infra-estrutura e manutenção para a implantação.
O MongoDB suporta escalonamento horizontal através de sharding.
Topologia
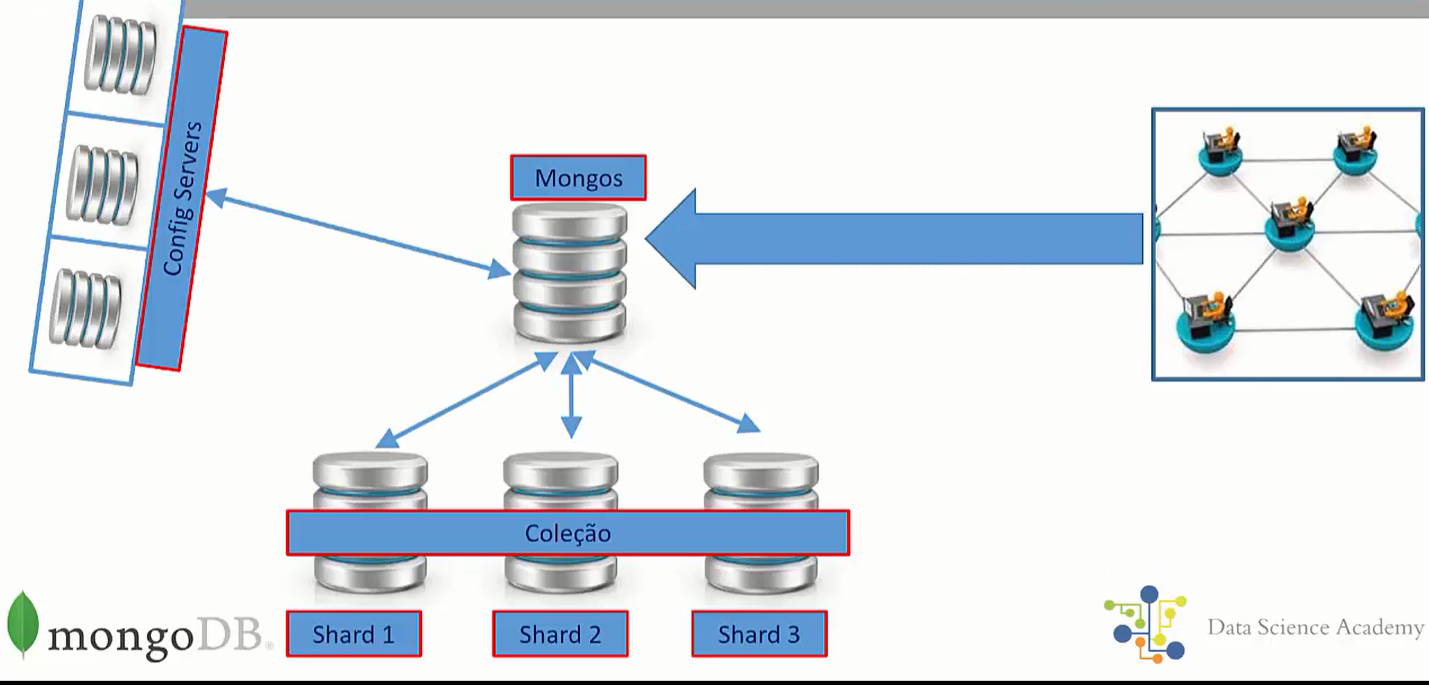
Um sharded cluster no MongoDB consiste nos seguintes componentes:
mongos: Este servidor atua como um roteador de consulta, fornecendo uma interface entre aplicativos cliente e o sharded cluster. Entenda que embora os dados estejam distribuídos em vários servidores, para a sua aplicação é como se os dados estivessem no mesmo servidor.
Servidores de configuração: Neles estão armazenados os metadados necessários para gerenciar a distribuição dos dados, ou seja, em qual servidor está cada documento? Para segurança da topologia, estes servidores devem estar replicados.
Shard Server: Servidor onde os dados da coleção estão armazenados.
O gráfico a seguir descreve a interação de componentes dentro de um sharded cluster:
Shard Keys
Para o MongoDB particionar os dados de uma coleção é preciso que os documentos tenham um ou alguns campos que vão compor a shard key.
A Shard Key representa o critério usado para distribuir os documentos nos servidores.
Imagine a seguinte situação, sua aplicação consulta a coleção particionada por data de cadastro. Nesta situação pode ser útil particionar a coleção por data de cadastro, deixando por exemplo os documentos de 2015 em um servidor, 2016 em outro e de 2017 em outro.
A escolha da shard key afeta o desempenho, eficiência e escalabilidade de um sharded cluster. Um cluster com o melhor hardware e infra-estrutura possível pode apresentar problemas se a escolha da shard key não for adequada.
Dica da Dani: Verifique como as suas queries acessam a coleção! E teste!!!
Métodos para dividir a coleção
Existem duas maneiras para dividir a coleção, Range ou Hash.
Usando o range, a coleção será dividida de acordo com intervalo de valores. Hash é quando o MongoDB cria um código para a shard key e faz o particionamento da coleção de acordo com ele.
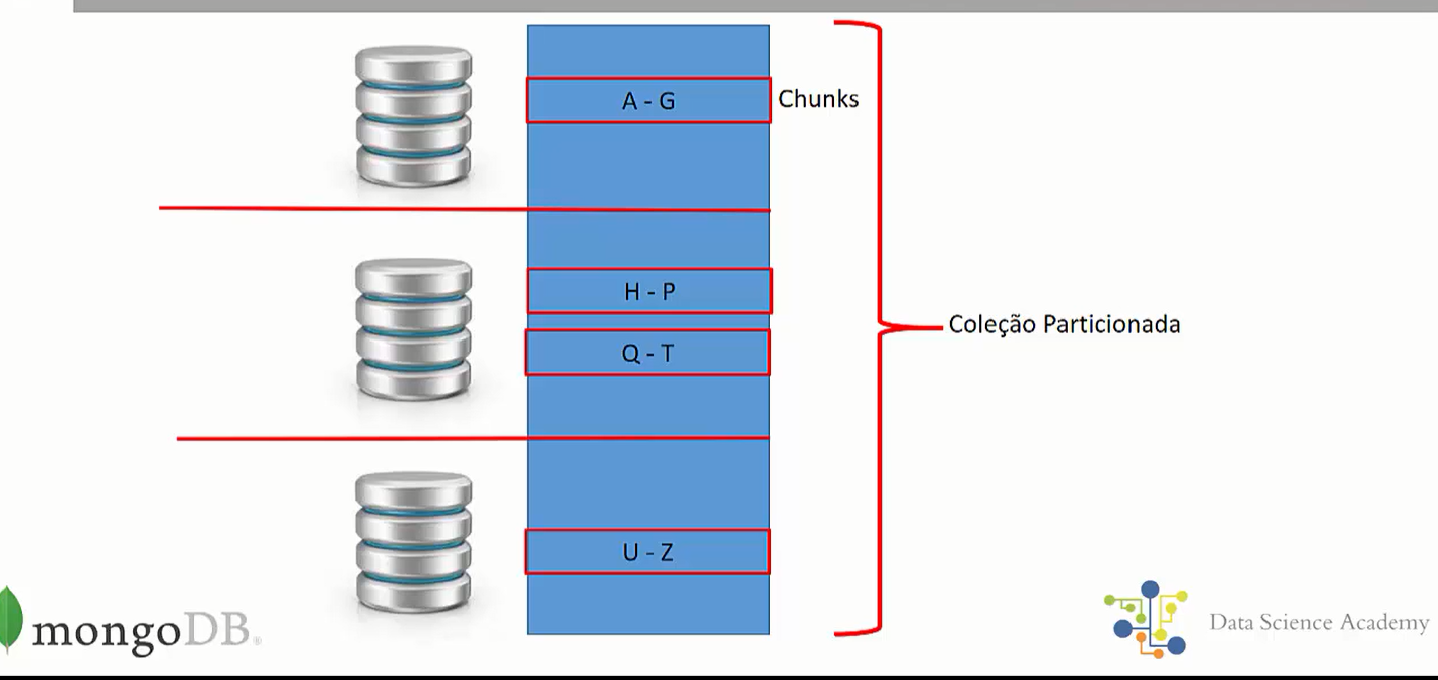
Chunk
Um chunk representa uma faixa de valores usada para dividir os documentos de uma coleção, gosto de dizer que um chunk é literalmente um pedaço de uma coleção. Só entenda que não é um pedaço aleatório é uma divisão de acordo com algum critério de valor.
Vantagens de usar o Sharding
Desempenho na leitura e escrita
A leitura e a escrita tende a ser muito mais rápida! As manipullações são realizadas em servidores específicos e em um subconjunto de documentos da coleção. Os recursos do servidor são utilizados para as manipulações de uma quantidade menor de documentos fazendo com que o processamento seja mais rápido.
Capacidade de armazenamento
O Sharding distribui dados através dos shards, permitindo que cada shard contenha um subconjunto dos dados. À medida que o conjunto de dados cresce, shards pode mser adicionados aumentando a capacidade de armazenamento do cluster.
Alta disponibilidade
Um shard cluster pode continuar a executar operações parciais de leitura/ gravação, mesmo que um ou mais servidores não estejam disponíveis. Ou seja somente parte dos dados fica inacessível.
Existe a possibilidade de replicar cada um dos shard servers!!! Implementando assim alta disponibilidade e melhor desempenho! (Eu te desafio a tentar fazer replicação e sharding juntos! Se precisar de uma ajuda… é só chamar que vamos juntos!)
Treino
Espero que você tenha compreendido os principais conceitos do particionamento dos dados no MongoDB. E neste caso é hora de ver tudo funcionando na prática.
Lembre-se que este roteiro serve para testes, uma vez que usaremos uma única máquina para ser config server, mongos e shard server. Em um ambiente de produção a topologia será mais complexa.
1- Criar o diretório de dados do servidor de configuração
Cd C:\Cursos\MongoDB\Sharding
mkdir cfg1
mkdir cfg2
mkdir cfg3
2- Iniciar os servidores de configuração. Serão 3. Porque estão replicados e o fator de replicação padrão é 3 (a opção start /b executa o comando em Segundo plano)
start /b mongod –configsvr –dbpath cfg1 –replSet conf –port 26051 –logpath log.cfg0 –logappend
start /b mongod –configsvr –dbpath cfg2 –replSet conf –port 26052 –logpath log.cfg1 –logappend
start /b mongod –configsvr –dbpath cfg3 –replSet conf –port 26053 –logpath log.cfg2 –logappend
Atenção que usamos a opção –configsvr indica que este é um servidor de configuração
3 – Configurar a replicação dos config servers
mongo –port 26051
rs.initiate(
{
_id: “conf”,
configsvr: true,
members: [
{ _id : 0, host : “localhost:26051” },
{ _id : 1, host : “localhost:26052” },
{ _id : 2, host : “localhost:26053” }
]
}
)
4– Veja que no diretório C:\Cursos\MongoDB\Sharding foram criados os arquivos de log log_cfg1.txt, log_cfg2.txt e log_cfg3.txt
5– Em um outro pompt de comando, Crie 3 diretórios de dados, um diretório para cada shard server.
Cd C:\Cursos\MongoDB\Sharding
mkdir S1
mkdir S2
mkdir S3
6– Iniciar os servidores
start /b mongod –shardsvr –port 27051 –dbpath .\s1 –logpath .\log_s1.txt –logappend –oplogSize 50
start /b mongod –shardsvr –port 27052 –dbpath .\s2 –logpath .\log_s2.txt –logappend –oplogSize 50
start /b mongod –shardsvr –port 27053 –dbpath .\s3 –logpath .\log_s3.txt –logappend –oplogSize 50
Atenção para a opção –shardsvr que indica que o servidor é um shard server
7- Verifique se os arquivos de log de cada servidor foram gerados corretamente
8- Iniciar um servidor mongos informando explicitamente quais são os servidores de configuração.
start /b mongos –configdb “conf/localhost:26051,localhost:26052,localhost:26053” –logpath log.mongos0 –port 27017
9– Veja que existem logs para todos os servidores que estão sendo executados
10– Conectar no mongoDB
mongo
11- Adicionar os shard servers ao objeto sh
sh.addShard(“localhost:27051”)
sh.addShard(“localhost:27052”)
sh.addShard(“localhost:27053”)
12 – Verificar o status do sharding
sh.status()
Dica da Dani… Observe as mensagens de retorno, não é complexo ver se os servidores foram adicionados corretamente… Neste caso você verá que os 3 servidores foram adicionados e que nenhum banco de dados particionado foi criado. Guarde este comando no coração!
13- Habilite um banco de dados para usar o particionamento e use-o
sh.enableSharding (“loja”)
use loja
14- Criar uma coleção com 20000 clientes
for (var i=0; i < 20000; i++ ) { db.c.insert ( { pos:i, dt: Date() } ) };
Comentário da Dani: Fala sério este comando é muito fofo! Ele contám um loop simples, que insere na coleção c 20000 documentos. O que você acha de exercitar suas habilidades de Dev e incrementar este script?
15- Criar um índice na coleção de clientes, para ser usado como shard key
db.c.createIndex ( { pos:1 }, { unique : true } )
Comentário da Dani: se fosse um índice do tipo hashed, faríamos: db.collection.createIndex( { _id: “hashed” } )
Lembrando que neste caso o índice não pode ser único nem composto. Que tal testar?
16- Particiona a coleção
sh.shardCollection (“loja.c”, {pos:1}, true)
17- Verifica como os dados da coleção c estão distribuídos nos 3 servidores shard
db.c.getShardDistribution()
Comentário da Dani: Veja que a distribuição dos documentos nas partições está desigual. Se quiser corrigir a distribuição, siga os passos abaixo (lembrando que é uma correção pontual!)
18- Pare o balanceamento feito pelo MongoDB
sh.stopBalancer()
19- Determine como os dados serão particionados. Neste caso decidi que os dados menores de 10000 ficarão no shard0000 e os dados maiores que 10000 serão movidos para o shard0002 (te desafio novamente… Mude a distribuição…)
sh.splitAt (“loja.c”, {pos:10000} )
20– Mover os dados para o shard desejado neste caso os dados maiores que 10000 serão movidos para o shard0002
sh.moveChunk ( “loja.c”, {pos:10000}, “shard0002” )
21– Verifique a distribuição dos dados
db.c.getShardDistribution()
21 – Reinicie o balancer
sh.startBalancer()
Conclusão
Para escalar horizontalmente o MongoDB permite que os dados de uma coleção sejam divididos entre vários servidores, e ainda garante que a aplicação não sofra modificações quando os dados forem particionados.
O particionamento no MongoDB tem o nome de sharding e em sua topologia possui os servidores do configuração (que devem ser replicados) que armazenam os metadados do particionamento, os shard servers que contém as partições dos dados (chamados de chunks), o servidor mongos que recebe as solicitações das aplicações e direciona as solicitações para os servidor onde os dados solicitados estão.
O sharding não é complexo (mas é um recurso avançado), mas precisa ser pensado, para que não degrade o desempenho das suas aplicações e nem aumente excessivamente a complexidade da infraestrutura.
Não me canso de falar… Altere os scripts de treino, teste, erre, corrija… Sinta-se seguro no seu ambiente de testes e tenho certeza que você será capaz de criar as melhores aplicações usando recursos avançados como o particionamento!
Se você tem alguma dúvida, é só me procurar no Twitter, ou no facebook, ou comentando este post, ou no formulário de contato. Não se preocupe… Eu sempre respondo (mesmo que seja para avisar que estou pesquisando).
Referências
Curso de gerenciamento de dados com MongoDB da Data Science Academy (Recomendo este curso mil vezes)

Gostou do que leu?
Inscreva-se e receba dicas como essa no seu e-mail!