No post de hoje conversaremos sobre os bancos de dados NoSQL orientados a colunas, e como exemplo usaremos o Cassandra, que é o mais conhecido desta categoria.
O combinado era de ter um post por semana, mas eu falhei nas últimas duas… Mas o motivo foi justo.
Semana retrasada dei uma boa acelerada na escrita do meu e-book sobre MongoDB, e semana passada perdi um ser muito especial, e não tive condições de escrever.
A boa notícia é que o e-book de MongoDB já está na revisão, e em breve será publicado em português e em inglês.
O que é o Banco de Dados Cassandra?
É um BD NoSQL, open source (desde 2008), escalável, rápido e orientado a colunas.
Para consultar os dados no Cassandra usamos uma linguagem chamada CQL (Cassandra Query Language) que é baseada no padrão SQL.
Apesar de usar uma linguagem parecida com o que já conhecemos, a forma como os dados são armazenados é um pouco diferente… Adoro esta imagem porque mostra como os dados são armazenados em um banco de dados relacional e no Cassandra:

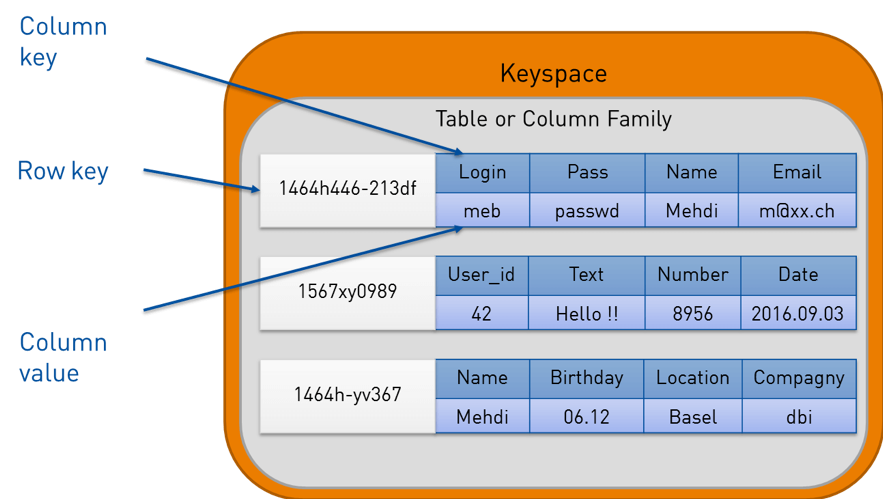
Resumindo tudo isso… e usando a definição linda do wikipedia “Apache Cassandra é um projeto de sistema gerenciador de banco de dados (SGBD) distribuído e altamente escalável, que reúne a arquitetura do DynamoDB, da Amazon Web Services e modelo de dados baseado no BigTable, do Google.
Ele foi inicialmente foi criado pelo Facebook, que abriu seu código-fonte para a comunidade em 2008. Agora ele é mantido por desenvolvedores da fundação Apache e colaboradores do mundo inteiro.”
O Cassandra é excelente quando precisamos de escalabilidade e alta disponibilidade sem comprometer o desempenho, mas eu particularmente acho a arquitetura e a configuração um pouco complicada.
Adoro o fato dele ter escalabilidade linear, porque me ajuda no levantamento do hardware necessário para os meus projetos. Lembrando que escalabilidade é a capacidade de um sistema crescer atendendo às demandas sem perder as qualidades que lhe agregam valor. A escalabilidade linear é previsível, e eu acho mais fácil de explicar com o seguinte exemplo:
3 servidores tem a capacidade de atender 30000 requisições por segundo. Se eu adicionar mais 2 servidores o sistema terá a capacidade de atender 50000 requisições por segundo. Simples e fofo assim.
A replicação no Cassandra é nativa, ou seja, os dados são replicados automaticamente para vários nós, e cada nó pode estar em um data center diferente. Os nós problemáticos podem ser substituídos sem tempo de inatividade, o que simplifica muito a vida do DBA (ok… de todo o time).
No MongoDB todas as escritas acontecem no nó primário, no Cassandra as escritas podem acontecer em qualquer nó (eles são idênticos e depois da escrita os dados serão replicados). Essa é uma característica linda, porque o Cassandra é fantástico para a escrita de grandes volumes de dados.
Momento opinião da Dani…
Acho o Cassandra um arraso! Adoro trabalhar com ele, mas vejo umas coisas que me dão calafrios e eu gostaria de te alertar para que você não cometa estes erros.
- No Cassandra não fazemos JOINS! Essa é a primeira regra!
- O modelo de dados do Cassandra começa com o entendimento das consultas que serão feitas.
- A redundância dos dados não é um problema!
- A escolha da chave primária é muito importante, e precisa ser pensada com cuidado para não deixar o seu banco de dados uma carroça.
A chave primária, a arquitetura e a fofoca…
Os dados no Cassandra são particionados automaticamente utilizando a partition key, que é o primeiro atributo da chave primária. As partições são então distribuídas entre os nós do cluster e o replicadas em múltiplos nós.
Como o Cassandra é distribuído, ele adota um protocolo chamado gossip (fofoca) para detectar nós com problemas. De tempos em tempos os nós do cluster (servidores) enviam mensagens entre eles, e caso algum nó falhe ao responder a essas mensagens, ele é marcado como um nó problemático, e ações corretivas são disparadas em background (como por exemplo replicar os dados que estavam no servidor problema para outros nós).
Outra coisa importante é pensar na consistência dos dados, porque isso afeta muito o desempenho do seu sistema.
Ao atualizar ou incluir um registro, devemos definir seus dados devem ser imediatamente replicados (consistência forte), ou se podemos aguardar para que os dados sejam replicados aos poucos, conforme a disponibilidade do cluster (consistência eventual).
Quanto mais forte a consistência, maior o impacto no desempenho.
DataStax e Cassandra… Qual a confusão?
Muitas empresas ainda temem utilizar SGBDs de código aberto, porque querem/ precisam de suporte, treinamentos entre outos requisitos. Por isso é importante verificar se existem distribuições do SGBD, ou empresas especializadas para ajudar na adoção destes produtos.
Uma distribuição do Cassandra que eu acho bem legal, é a da DataStax, porque tem algumas particularidades para a adoção em grandes empresas e também a DataStax é uma das colaboradoras do Cassandra.
Quando usar o Cassandra?
Em 2014 um amigo querido, e meu “muso” quando o assunto é Cassandra, o Otávio Santana, escreveu: “Antes de escolher uma tecnologia é muito importante entender bem o seu problema e em seguida entender o motivo pelo qual a tecnologia escolhida será útil em seu projeto. Com o Cassandra não é diferente, ele é um banco NOSQL é interessante seu uso quando se precisa de uma alta disponibilidade e tolerância a falhas (seria o A e o P no teorema do CAP). “
Indo direto ao ponto… Use o Cassandra se:
- Você conhece as suas consultas;
- Se tem um alto volume de dados;
- Se tem mais de 3 servidores;
- Dados desnormalizados;
- Quando você tiver tempo e recursos para modelar os dados;
- Não precisa de transações;
- Não precisa de integridade referencial;
Amigos, não estou fazendo propaganda dos Arquitetos de Dados, mas sem um modelo correto fica impossível tomar algumas decisões. Sendo assim invista tempo nesta etapa ou o seu projeto com Cassandra tende a falhar.
Para finalizar o post e sem fechar o assunto…
Dando continuidade em nossa super planilha, adicionei mais uma aba, indicando quando usar o Cassandra.
Lembre-se que a planilha é nossa, então fique à vontade para mandar suas colaborações.
Os outros posts da série SQL ou NoSQL…
Se você perdeu os outros posts desta série, te convido para ler:
SQL ou NoSQL? (Parte 2 – Porque MongoDB?)
SQL ou NoSQL? Parte 3 – Quando usar o Neo4J?
SQL ou NoSQL? Você conhece o Redis?
Dados de Alto Valor
Eu sou uma pessoa inquieta… Por isso eu estou criando um conteúdo fofo para ajudar Devs e DBAs a implantar, otimizar e propor arquiteturas de dados complexas utilizando novas tecnologias, para que participem ativamente da criação de novos produtos e se tornem referência nas empresas.
Aguardem! E se inscrevam aqui no blog, para conhecer este programa incrível.
E-book
Nas próximas semanas eu lançarei meu e-book sobre MongoDB, e ele será disponibilizado primeiramente para os leitores do blog, então se inscreva e aguarde as cenas dos próximos capítulos!
Referências
Leiam os posts abaixo para conhecer mais sobre o Cassandra! São incríveis e me ajudaram muito na escrita deste post.
https://pt.wikipedia.org/wiki/Apache_Cassandra
https://www.devmedia.com.br/introducao-ao-cassandra/38377
https://medium.com/nstech/apache-cassandra-8250e9f30942
Patrocinador
Amigos, vocês conhecem o nosso apoiador?
O nosso primeiro parceiro é a SPEsportes, uma loja super legal, com produtos incríveis e preço justo! Os leitores do blog tem desconto de 20% em todos os produtos, informando o cupom de desconto DB4BEGINNERS
Se a sua empresa quiser ser parceira também, temos algumas possibilidades.
Autora

 |  |  |  |  |

Gostou do que leu?
Inscreva-se e receba dicas como essa no seu e-mail!